AUTHORS:
Elements of free string monoids, internal representation subject to change.
These are special classes of free monoid elements with distinct printing.
The internal representation of elements does not use the exponential compression of FreeMonoid elements (a feature), and could be packed into words.
Bases: sage.monoids.free_monoid_element.FreeMonoidElement
Element of a free string monoid.
Return the count of each unique character.
EXAMPLES:
Count the character frequency in an object comprised of capital letters of the English alphabet:
sage: M = AlphabeticStrings().encoding("abcabf")
sage: sorted(M.character_count().items())
[(A, 2), (B, 2), (C, 1), (F, 1)]
In an object comprised of binary numbers:
sage: M = BinaryStrings().encoding("abcabf")
sage: sorted(M.character_count().items())
[(0, 28), (1, 20)]
In an object comprised of octal numbers:
sage: A = OctalStrings()
sage: M = A([1, 2, 3, 2, 5, 3])
sage: sorted(M.character_count().items())
[(1, 1), (2, 2), (3, 2), (5, 1)]
In an object comprised of hexadecimal numbers:
sage: A = HexadecimalStrings()
sage: M = A([1, 2, 4, 6, 2, 4, 15])
sage: sorted(M.character_count().items())
[(1, 1), (2, 2), (4, 2), (6, 1), (f, 1)]
In an object comprised of radix-64 characters:
sage: A = Radix64Strings()
sage: M = A([1, 2, 63, 45, 45, 10]); M
BC/ttK
sage: sorted(M.character_count().items())
[(B, 1), (C, 1), (K, 1), (t, 2), (/, 1)]
TESTS:
Empty strings return no counts of character frequency:
sage: M = AlphabeticStrings().encoding("")
sage: M.character_count()
{}
sage: M = BinaryStrings().encoding("")
sage: M.character_count()
{}
sage: A = OctalStrings()
sage: M = A([])
sage: M.character_count()
{}
sage: A = HexadecimalStrings()
sage: M = A([])
sage: M.character_count()
{}
sage: A = Radix64Strings()
sage: M = A([])
sage: M.character_count()
{}
The byte string associated to a binary or hexadecimal string monoid element.
EXAMPLES:
sage: S = HexadecimalStrings()
sage: s = S.encoding("A..Za..z"); s
412e2e5a612e2e7a
sage: s.decoding()
'A..Za..z'
sage: s = S.encoding("A..Za..z",padic=True); s
14e2e2a516e2e2a7
sage: s.decoding()
'\x14\xe2\xe2\xa5\x16\xe2\xe2\xa7'
sage: s.decoding(padic=True)
'A..Za..z'
sage: S = BinaryStrings()
sage: s = S.encoding("A..Za..z"); s
0100000100101110001011100101101001100001001011100010111001111010
sage: s.decoding()
'A..Za..z'
sage: s = S.encoding("A..Za..z",padic=True); s
1000001001110100011101000101101010000110011101000111010001011110
sage: s.decoding()
'\x82ttZ\x86tt^'
sage: s.decoding(padic=True)
'A..Za..z'
Returns the probability space of character frequencies. The output
of this method is different from that of the method
characteristic_frequency().
One can think of the characteristic frequency probability of an
element in an alphabet 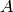 as the expected probability of that element
occurring. Let
as the expected probability of that element
occurring. Let 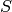 be a string encoded using elements of . The
frequency probability distribution corresponding to provides us
with the frequency probability of each element of as observed
occurring in . Thus one distribution provides expected
probabilities, while the other provides observed probabilities.
be a string encoded using elements of . The
frequency probability distribution corresponding to provides us
with the frequency probability of each element of as observed
occurring in . Thus one distribution provides expected
probabilities, while the other provides observed probabilities.
INPUT:
EXAMPLES:
Capital letters of the English alphabet:
sage: M = AlphabeticStrings().encoding("abcd")
sage: L = M.frequency_distribution().function()
sage: sorted(L.items())
<BLANKLINE>
[(A, 0.250000000000000),
(B, 0.250000000000000),
(C, 0.250000000000000),
(D, 0.250000000000000)]
The binary number system:
sage: M = BinaryStrings().encoding("abcd")
sage: L = M.frequency_distribution().function()
sage: sorted(L.items())
[(0, 0.593750000000000), (1, 0.406250000000000)]
The hexadecimal number system:
sage: M = HexadecimalStrings().encoding("abcd")
sage: L = M.frequency_distribution().function()
sage: sorted(L.items())
<BLANKLINE>
[(1, 0.125000000000000),
(2, 0.125000000000000),
(3, 0.125000000000000),
(4, 0.125000000000000),
(6, 0.500000000000000)]
Get the observed frequency probability distribution of digrams in the string “ABCD”. This string consists of the following digrams: “AB”, “BC”, and “CD”. Now find out the frequency probability of each of these digrams as they occur in the string “ABCD”:
sage: M = AlphabeticStrings().encoding("abcd")
sage: D = M.frequency_distribution(length=2).function()
sage: sorted(D.items())
[(AB, 0.333333333333333), (BC, 0.333333333333333), (CD, 0.333333333333333)]
