Next we illustrate how to load programs written in a separate file into Sage. Create a file called example.sage with the following content:
print "Hello World"
print 2^3
You can read in and execute example.sage file using the load command.
sage: load "example.sage"
Hello World
8
You can also attach a Sage file to a running session using the attach command:
sage: attach "example.sage"
Hello World
8
Now if you change example.sage and enter one blank line into Sage (i.e., hit return), then the contents of example.sage will be automatically reloaded into Sage.
In particular, attach automatically reloads a file whenever it changes, which is handy when debugging code, whereas load only loads a file once.
When Sage loads example.sage it converts it to Python, which is then executed by the Python interpreter. This conversion is minimal; it mainly involves wrapping integer literals in Integer() floating point literals in RealNumber(), replacing ^‘s by **‘s, and replacing e.g., R.2 by R.gen(2)}. The converted version of example.sage is contained in the same directory as example.sage and is called example.sage.py. This file contains the following code:
print "Hello World"
print Integer(2)**Integer(3)
Integer literals are wrapped and the ^ is replaced by a **. (In Python ^ means “exclusive or” and ** means “exponentiation”.)
This preparsing is implemented in sage/misc/interpreter.py.)
You can paste multi-line indented code into Sage as long as there are newlines to make new blocks (this is not necessary in files). However, the best way to enter such code into Sage is to save it to a file and use attach, as described above.
Speed is crucial in mathematical computations. Though Python is a convenient very high-level language, certain calculations can be several orders of magnitude faster than in Python if they are implemented using static types in a compiled language. Some aspects of Sage would have been too slow if it had been written entirely in Python. To deal with this, Sage supports a compiled “version” of Python called Cython ([Cyt] and [Pyr]). Cython is simultaneously similar to both Python and C. Most Python constructions, including list comprehensions, conditional expressions, code like += are allowed; you can also import code that you have written in other Python modules. Moreover, you can declare arbitrary C variables, and arbitrary C library calls can be made directly. The resulting code is converted to C and compiled using a C compiler.
In order to make your own compiled Sage code, give the file an .spyx extension (instead of .sage). If you are working with the command-line interface, you can attach and load compiled code exactly like with interpreted code (at the moment, attaching and loading Cython code is not supported with the notebook interface). The actual compilation is done “behind the scenes” without your having to do anything explicit. See $SAGE_ROOT/examples/programming/sagex/factorial.spyx for an example of a compiled implementation of the factorial function that directly uses the GMP C library. To try this out for yourself, cd to $SAGE_ROOT/examples/programming/sagex/, then do the following:
sage: load "factorial.spyx"
***************************************************
Recompiling factorial.spyx
***************************************************
sage: factorial(50)
30414093201713378043612608166064768844377641568960512000000000000L
sage: time n = factorial(10000)
CPU times: user 0.03 s, sys: 0.00 s, total: 0.03 s
Wall time: 0.03
Here the trailing L indicates a Python long integer (see The Pre-Parser: Differences between Sage and Python).
Note that Sage will recompile factorial.spyx if you quit and restart Sage. The compiled shared object library is stored under $HOME/.sage/temp/hostname/pid/spyx. These files are deleted when you exit Sage.
NO Sage preparsing is applied to spyx files, e.g., 1/3 will result in
0 in a spyx file instead of the rational number 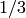 . If
foo is a function in the Sage library, to use it from a spyx file
import sage.all and use sage.all.foo.
. If
foo is a function in the Sage library, to use it from a spyx file
import sage.all and use sage.all.foo.
import sage.all
def foo(n):
return sage.all.factorial(n)
It is also easy to access C functions defined in separate *.c files. Here’s an example. Create files test.c and test.spyx in the same directory with contents:
The pure C code: test.c
int add_one(int n) {
return n + 1;
}
The Cython code: test.spyx:
cdef extern from "test.c":
int add_one(int n)
def test(n):
return add_one(n)
Then the following works:
sage: attach "test.spyx"
Compiling (...)/test.spyx...
sage: test(10)
11
If an additional library foo is needed to compile the C code generated from a Cython file, add the line clib foo to the Cython source. Similarly, an additional C file bar can be included in the compilation with the declaration cfile bar.
The following standalone Sage script factors integers, polynomials, etc:
#!/usr/bin/env sage -python
import sys
from sage.all import *
if len(sys.argv) != 2:
print "Usage: %s <n>"%sys.argv[0]
print "Outputs the prime factorization of n."
sys.exit(1)
print factor(sage_eval(sys.argv[1]))
In order to use this script, your SAGE_ROOT must be in your PATH. If the above script is called factor, here is an example usage:
bash $ ./factor 2006
2 * 17 * 59
bash $ ./factor "32*x^5-1"
(2*x - 1) * (16*x^4 + 8*x^3 + 4*x^2 + 2*x + 1)
Every object in Sage has a well-defined type. Python has a wide range of basic built-in types, and the Sage library adds many more. Some built-in Python types include strings, lists, tuples, ints and floats, as illustrated:
sage: s = "sage"; type(s)
<type 'str'>
sage: s = 'sage'; type(s) # you can use either single or double quotes
<type 'str'>
sage: s = [1,2,3,4]; type(s)
<type 'list'>
sage: s = (1,2,3,4); type(s)
<type 'tuple'>
sage: s = int(2006); type(s)
<type 'int'>
sage: s = float(2006); type(s)
<type 'float'>
To this, Sage adds many other types. E.g., vector spaces:
sage: V = VectorSpace(QQ, 1000000); V
Vector space of dimension 1000000 over Rational Field
sage: type(V)
<class 'sage.modules.free_module.FreeModule_ambient_field_with_category'>
Only certain functions can be called on V. In other math software systems, these would be called using the “functional” notation foo(V,...). In Sage, certain functions are attached to the type (or class) of V, and are called using an object-oriented syntax like in Java or C++, e.g., V.foo(...). This helps keep the global namespace from being polluted with tens of thousands of functions, and means that many different functions with different behavior can be named foo, without having to use type-checking of arguments (or case statements) to decide which to call. Also, if you reuse the name of a function, that function is still available (e.g., if you call something zeta, then want to compute the value of the Riemann-Zeta function at 0.5, you can still type s=.5; s.zeta()).
sage: zeta = -1
sage: s=.5; s.zeta()
-1.46035450880959
In some very common cases, the usual functional notation is also supported for convenience and because mathematical expressions might look confusing using object-oriented notation. Here are some examples.
sage: n = 2; n.sqrt()
sqrt(2)
sage: sqrt(2)
sqrt(2)
sage: V = VectorSpace(QQ,2)
sage: V.basis()
[
(1, 0),
(0, 1)
]
sage: basis(V)
[
(1, 0),
(0, 1)
]
sage: M = MatrixSpace(GF(7), 2); M
Full MatrixSpace of 2 by 2 dense matrices over Finite Field of size 7
sage: A = M([1,2,3,4]); A
[1 2]
[3 4]
sage: A.charpoly('x')
x^2 + 2*x + 5
sage: charpoly(A, 'x')
x^2 + 2*x + 5
To list all member functions for 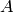 , use tab completion.
Just type A., then type the [tab] key on your keyboard, as
explained in Reverse Search and Tab Completion.
, use tab completion.
Just type A., then type the [tab] key on your keyboard, as
explained in Reverse Search and Tab Completion.
The list data type stores elements of arbitrary type. Like in C,
C++, etc. (but unlike most standard computer algebra systems), the
elements of the list are indexed starting from 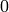 :
:
sage: v = [2, 3, 5, 'x', SymmetricGroup(3)]; v
[2, 3, 5, 'x', Symmetric group of order 3! as a permutation group]
sage: type(v)
<type 'list'>
sage: v[0]
2
sage: v[2]
5
(When indexing into a list, it is OK if the index is not a Python int!) A Sage Integer (or Rational, or anything with an __index__ method) will work just fine.
sage: v = [1,2,3]
sage: v[2]
3
sage: n = 2 # SAGE Integer
sage: v[n] # Perfectly OK!
3
sage: v[int(n)] # Also OK.
3
The range function creates a list of Python int’s (not Sage Integers):
sage: range(1, 15)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
This is useful when using list comprehensions to construct lists:
sage: L = [factor(n) for n in range(1, 15)]
sage: print L
[1, 2, 3, 2^2, 5, 2 * 3, 7, 2^3, 3^2, 2 * 5, 11, 2^2 * 3, 13, 2 * 7]
sage: L[12]
13
sage: type(L[12])
<class 'sage.structure.factorization.Factorization'>
sage: [factor(n) for n in range(1, 15) if is_odd(n)]
[1, 3, 5, 7, 3^2, 11, 13]
For more about how to create lists using list comprehensions, see [PyT].
List slicing is a wonderful feature. If L
is a list, then L[m:n] returns the sublist of L obtained by
starting at the 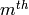 element and stopping at the
element and stopping at the
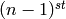 element, as illustrated below.
element, as illustrated below.
sage: L = [factor(n) for n in range(1, 20)]
sage: L[4:9]
[5, 2 * 3, 7, 2^3, 3^2]
sage: print L[:4]
[1, 2, 3, 2^2]
sage: L[14:4]
[]
sage: L[14:]
[3 * 5, 2^4, 17, 2 * 3^2, 19]
Tuples are similar to lists, except they are immutable, meaning once they are created they can’t be changed.
sage: v = (1,2,3,4); v
(1, 2, 3, 4)
sage: type(v)
<type 'tuple'>
sage: v[1] = 5
...
TypeError: 'tuple' object does not support item assignment
Sequences are a third list-oriented Sage type. Unlike lists and tuples, Sequence is not a built-in Python type. By default, a sequence is mutable, but using the Sequence class method set_immutable, it can be set to be immutable, as the following example illustrates. All elements of a sequence have a common parent, called the sequences universe.
sage: v = Sequence([1,2,3,4/5])
sage: v
[1, 2, 3, 4/5]
sage: type(v)
<class 'sage.structure.sequence.Sequence'>
sage: type(v[1])
<type 'sage.rings.rational.Rational'>
sage: v.universe()
Rational Field
sage: v.is_immutable()
False
sage: v.set_immutable()
sage: v[0] = 3
...
ValueError: object is immutable; please change a copy instead.
Sequences derive from lists and can be used anywhere a list can be used:
sage: v = Sequence([1,2,3,4/5])
sage: isinstance(v, list)
True
sage: list(v)
[1, 2, 3, 4/5]
sage: type(list(v))
<type 'list'>
As another example, basis for vector spaces are immutable sequences, since it’s important that you don’t change them.
sage: V = QQ^3; B = V.basis(); B
[
(1, 0, 0),
(0, 1, 0),
(0, 0, 1)
]
sage: type(B)
<class 'sage.structure.sequence.Sequence'>
sage: B[0] = B[1]
...
ValueError: object is immutable; please change a copy instead.
sage: B.universe()
Vector space of dimension 3 over Rational Field
A dictionary (also sometimes called an associative array) is a mapping from ‘hashable’ objects (e.g., strings, numbers, and tuples of such; see the Python documentation http://docs.python.org/tut/node7.html and http://docs.python.org/lib/typesmapping.html for details) to arbitrary objects.
sage: d = {1:5, 'sage':17, ZZ:GF(7)}
sage: type(d)
<type 'dict'>
sage: d.keys()
[1, 'sage', Integer Ring]
sage: d['sage']
17
sage: d[ZZ]
Finite Field of size 7
sage: d[1]
5
The third key illustrates that the indexes of a dictionary can be complicated, e.g., the ring of integers.
You can turn the above dictionary into a list with the same data:
sage: d.items()
[(1, 5), ('sage', 17), (Integer Ring, Finite Field of size 7)]
A common idiom is to iterate through the pairs in a dictionary:
sage: d = {2:4, 3:9, 4:16}
sage: [a*b for a, b in d.iteritems()]
[8, 27, 64]
A dictionary is unordered, as the last output illustrates.
Python has a built-in set type. The main feature it offers is very fast lookup of whether an element is in the set or not, along with standard set-theoretic operations.
sage: X = set([1,19,'a']); Y = set([1,1,1, 2/3])
sage: X
set(['a', 1, 19])
sage: Y
set([1, 2/3])
sage: 'a' in X
True
sage: 'a' in Y
False
sage: X.intersection(Y)
set([1])
Sage also has its own set type that is (in some cases) implemented using the built-in Python set type, but has a little bit of extra Sage-related functionality. Create a Sage set using Set(...). For example,
sage: X = Set([1,19,'a']); Y = Set([1,1,1, 2/3])
sage: X
{'a', 1, 19}
sage: Y
{1, 2/3}
sage: X.intersection(Y)
{1}
sage: print latex(Y)
\left\{1, \frac{2}{3}\right\}
sage: Set(ZZ)
Set of elements of Integer Ring
Iterators are a recent addition to Python that are particularly
useful in mathematics applications. Here are several examples; see
[PyT] for more details. We make an iterator over the squares of the
nonnegative integers up to 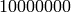 .
.
sage: v = (n^2 for n in xrange(10000000))
sage: v.next()
0
sage: v.next()
1
sage: v.next()
4
We create an iterate over the primes of the form 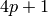 with
with 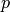 also prime, and look at the first few values.
also prime, and look at the first few values.
sage: w = (4*p + 1 for p in Primes() if is_prime(4*p+1))
sage: w # in the next line, 0xb0853d6c is a random 0x number
<generator object at 0xb0853d6c>
sage: w.next()
13
sage: w.next()
29
sage: w.next()
53
Certain rings, e.g., finite fields and the integers have iterators associated to them:
sage: [x for x in GF(7)]
[0, 1, 2, 3, 4, 5, 6]
sage: W = ((x,y) for x in ZZ for y in ZZ)
sage: W.next()
(0, 0)
sage: W.next()
(0, 1)
sage: W.next()
(0, -1)
We have seen a few examples already of some common uses of for loops. In Python, a for loop has an indented structure, such as
>>> for i in range(5):
print(i)
0
1
2
3
4
Note the colon at the end of the for statement (there is no “do” or “od” as in GAP or Maple), and the indentation before the “body” of the loop, namely print(i). This indentation is important. In Sage, the indentation is automatically put in for you when you hit enter after a “:”, as illustrated below.
sage: for i in range(5):
... print(i) # now hit enter twice
0
1
2
3
4
The symbol = is used for assignment. The symbol == is used to check for equality:
sage: for i in range(15):
... if gcd(i,15) == 1:
... print(i)
1
2
4
7
8
11
13
14
Keep in mind how indentation determines the block structure for if, for, and while statements:
sage: def legendre(a,p):
... is_sqr_modp=-1
... for i in range(p):
... if a % p == i^2 % p:
... is_sqr_modp=1
... return is_sqr_modp
sage: legendre(2,7)
1
sage: legendre(3,7)
-1
Of course this is not an efficient implementation of the Legendre symbol! It is meant to illustrate various aspects of Python/Sage programming. The function {kronecker}, which comes with Sage, computes the Legendre symbol efficiently via a C-library call to PARI.
Finally, we note that comparisons, such as ==, !=, <=, >=, >, <, between numbers will automatically convert both numbers into the same type if possible:
sage: 2 < 3.1; 3.1 <= 1
True
False
sage: 2/3 < 3/2; 3/2 < 3/1
True
True
Almost any two objects may be compared; there is no assumption that the objects are equipped with a total ordering.
sage: 2 < CC(3.1,1)
True
sage: 5 < VectorSpace(QQ,3) # output can be somewhat random
True
Use bool for symbolic inequalities:
sage: x < x + 1
x < x + 1
sage: bool(x < x + 1)
True
When comparing objects of different types in Sage, in most cases Sage tries to find a canonical coercion of both objects to a common parent. If successful, the comparison is performed between the coerced objects; if not successful the objects are considered not equal. For testing whether two variables reference the same object use is. For example:
sage: 1 is 2/2
False
sage: 1 is 1
False
sage: 1 == 2/2
True
In the following two lines, the first equality is False because
there is no canonical morphism 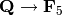 , hence no
canonical way to compare the
, hence no
canonical way to compare the 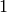 in
in 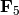 to the
to the
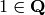 . In contrast, there is a canonical map
. In contrast, there is a canonical map
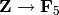 , hence the second comparison is True. Note
also that the order doesn’t matter.
, hence the second comparison is True. Note
also that the order doesn’t matter.
sage: GF(5)(1) == QQ(1); QQ(1) == GF(5)(1)
False
False
sage: GF(5)(1) == ZZ(1); ZZ(1) == GF(5)(1)
True
True
sage: ZZ(1) == QQ(1)
True
WARNING: Comparison in Sage is more restrictive than in Magma, which
declares the 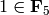 equal to .
equal to .
sage: magma('GF(5)!1 eq Rationals()!1') # optional magma required
true
Section Author: Martin Albrecht (malb@informatik.uni-bremen.de)
“Premature optimization is the root of all evil.” - Donald Knuth
Sometimes it is useful to check for bottlenecks in code to understand which parts take the most computational time; this can give a good idea of which parts to optimize. Python and therefore Sage offers several profiling–as this process is called–options.
The simplest to use is the prun command in the interactive shell. It returns a summary describing which functions took how much computational time. To profile (the currently slow! - as of version 1.0) matrix multiplication over finite fields, for example, do:
sage: k,a = GF(2**8, 'a').objgen()
sage: A = Matrix(k,10,10,[k.random_element() for _ in range(10*10)])
sage: %prun B = A*A
32893 function calls in 1.100 CPU seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
12127 0.160 0.000 0.160 0.000 :0(isinstance)
2000 0.150 0.000 0.280 0.000 matrix.py:2235(__getitem__)
1000 0.120 0.000 0.370 0.000 finite_field_element.py:392(__mul__)
1903 0.120 0.000 0.200 0.000 finite_field_element.py:47(__init__)
1900 0.090 0.000 0.220 0.000 finite_field_element.py:376(__compat)
900 0.080 0.000 0.260 0.000 finite_field_element.py:380(__add__)
1 0.070 0.070 1.100 1.100 matrix.py:864(__mul__)
2105 0.070 0.000 0.070 0.000 matrix.py:282(ncols)
...
Here ncalls is the number of calls, tottime is the total time spent in the given function (and excluding time made in calls to sub-functions), percall is the quotient of tottime divided by ncalls. cumtime is the total time spent in this and all sub-functions (i.e., from invocation until exit), percall is the quotient of cumtime divided by primitive calls, and filename:lineno(function) provides the respective data of each function. The rule of thumb here is: The higher the function in that listing, the more expensive it is. Thus it is more interesting for optimization.
As usual, prun? provides details on how to use the profiler and understand the output.
The profiling data may be written to an object as well to allow closer examination:
sage: %prun -r A*A
sage: stats = _
sage: stats?
Note: entering stats = prun -r A\*A displays a syntax error message because prun is an IPython shell command, not a regular function.
For a nice graphical representation of profiling data, you can use the hotshot profiler, a small script called hotshot2cachetree and the program kcachegrind (Unix only). The same example with the hotshot profiler:
sage: k,a = GF(2**8, 'a').objgen()
sage: A = Matrix(k,10,10,[k.random_element() for _ in range(10*10)])
sage: import hotshot
sage: filename = "pythongrind.prof"
sage: prof = hotshot.Profile(filename, lineevents=1)
sage: prof.run("A*A")
<hotshot.Profile instance at 0x414c11ec>
sage: prof.close()
This results in a file pythongrind.prof in the current working directory. It can now be converted to the cachegrind format for visualization.
On a system shell, type
hotshot2calltree -o cachegrind.out.42 pythongrind.prof
The output file cachegrind.out.42 can now be examined with kcachegrind. Please note that the naming convention cachegrind.out.XX needs to be obeyed.
