Weave is a tool that does for C/C++ what f2py does for fortran (though we should note it is also possible to wrap C code using f2py). Suppose we have some data stored in numpy arrays and we want to write some C/C++ code to do something with that data that needs to be fast. For a trivial example, let us write a function that sums the contents of a numpy array
import weave
from weave import converters
def my_sum(a):
n=int(len(a))
code="""
int i;
long int counter;
counter =0;
for(i=0;i<n;i++){
counter=counter+a(i);
}
return_val=counter;
"""
err=weave.inline(code,['a','n'],type_converters=converters.blitz,compiler='gcc')
return err
To call this function try
import numpy
a=numpy.array(range(60000))
time my_sum(a)
time sum(range(60000))
The first time the weave code executes the code is compiled, from
then on, the execution is immediate. You should find that python’s
built-in sum function is comparable in speed to what we just wrote.
Let us explain some things about this example. As you can see, to
use weave you create a string containing pure C/C++ code. Then you
call weave.inline on it. You pass to weave the string with the
code, as well as a list of python object that it is to
automatically convert to C variables. So in our case we can refer
to the python objects  and
and 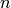 inside of weave.
Numpy arrays are accessed by
inside of weave.
Numpy arrays are accessed by 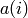 if they are
one-dimensional or
if they are
one-dimensional or 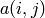 if they are two dimensional. Of
course we cannot use just any python object, currently weave knows
about all python numerical data types such as ints and floats, as
well as numpy arrays. Note that numpy arrays do not become pointers
in the C code (which is why they are accessed by ( ) and not [ ].
If you need a pointer you should copy the data into a pointer. Next
is a more complicated example that calls lapack to solve a linear
system ax=b.
if they are two dimensional. Of
course we cannot use just any python object, currently weave knows
about all python numerical data types such as ints and floats, as
well as numpy arrays. Note that numpy arrays do not become pointers
in the C code (which is why they are accessed by ( ) and not [ ].
If you need a pointer you should copy the data into a pointer. Next
is a more complicated example that calls lapack to solve a linear
system ax=b.
def weave_solve(a,b):
n = len(a[0])
x = numpy.array([0]*n,dtype=float)
support_code="""
#include <stdio.h>
extern "C" {
void dgesv_(int *size, int *flag,double* data,int*size,
int*perm,double*vec,int*size,int*ok);
}
"""
code="""
int i,j;
double* a_c;
double* b_c;
int size;
int flag;
int* p;
int ok;
size=n;
flag=1;
a_c= (double *)malloc(sizeof(double)*n*n);
b_c= (double *)malloc(sizeof(double)*n);
p = (int*)malloc(sizeof(int)*n);
for(i=0;i<n;i++)
{
b_c[i]=b(i);
for(j=0;j<n;j++)
a_c[i*n+j]=a(i,j);
}
dgesv_(&size,&flag,a_c,&size,p,b_c,&size,&ok);
for(i=0;i<n;i++)
x(i)=b_c[i];
free(a_c);
free(b_c);
free(p);
"""
libs=['lapack','blas','g2c']
dirs=['/media/sdb1/sage-2.6.linux32bit-i686-Linux']
vars = ['a','b','x','n']
weave.inline(code,vars,support_code=support_code,libraries=libs,library_dirs=dirs, \
type_converters=converters.blitz,compiler='gcc')
return x
Note that we have used the support_code argument which is additional C code you can use to include headers and declare functions. Note that inline also can take all distutils compiler options which we used here to link in lapack.
def weaveTimeStep(u,dx,dy):
"""Takes a time step using inlined C code -- this version uses
blitz arrays."""
nx, ny = u.shape
dx2, dy2 = dx**2, dy**2
dnr_inv = 0.5/(dx2 + dy2)
code = """
double tmp, err, diff,dnr_inv_;
dnr_inv_=dnr_inv;
err = 0.0;
for (int i=1; i<nx-1; ++i) {
for (int j=1; j<ny-1; ++j) {
tmp = u(i,j);
u(i,j) = ((u(i-1,j) + u(i+1,j))*dy2 +
(u(i,j-1) + u(i,j+1))*dx2)*dnr_inv_;
diff = u(i,j) - tmp;
err += diff*diff;
}
}
return_val = sqrt(err);
"""
# compiler keyword only needed on windows with MSVC installed
err = weave.inline(code, ['u', 'dx2', 'dy2', 'dnr_inv', 'nx','ny'],
type_converters = converters.blitz,
compiler = 'gcc')
return u,err
Using our previous driver you should find that this version takes about the same amount of time as the f2py version around .2 seconds to do 2750 iterations.
For more about weave see the weave tutorial at http://projects.scipy.org/scipy/scipy/browser/trunk/Lib/weave/doc/tutorial.html?format=raw
