The following code solves Laplace’s equation in parallel on a grid.
It divides a square into 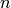 parallel strips where
is the number of processes and uses jacobi-iteration.
The way the code works is that the root process creates a matrix
and distributes the pieces to the other processes. At each
iteration each process passes its upper row to the process above
and its lower row to the process below since they need to know the
values at neighboring points to do the iteration. Then they iterate
and repeat. Every 500 iterations the error estimates from the
processes are collected using Gather. you can compare the output of
this with the solver we wrote in the section on f2py.
parallel strips where
is the number of processes and uses jacobi-iteration.
The way the code works is that the root process creates a matrix
and distributes the pieces to the other processes. At each
iteration each process passes its upper row to the process above
and its lower row to the process below since they need to know the
values at neighboring points to do the iteration. Then they iterate
and repeat. Every 500 iterations the error estimates from the
processes are collected using Gather. you can compare the output of
this with the solver we wrote in the section on f2py.
from mpi4py import MPI
import numpy
size=MPI.size
rank=MPI.rank
num_points=500
sendbuf=[]
root=0
dx=1.0/(num_points-1)
from numpy import r_
j=numpy.complex(0,1)
rows_per_process=num_points/size
max_iter=5000
num_iter=0
total_err=1
def numpyTimeStep(u,dx,dy):
dx2, dy2 = dx**2, dy**2
dnr_inv = 0.5/(dx2 + dy2)
u_old=u.copy()
# The actual iteration
u[1:-1, 1:-1] = ((u[0:-2, 1:-1] + u[2:, 1:-1])*dy2 +
(u[1:-1,0:-2] + u[1:-1, 2:])*dx2)*dnr_inv
v = (u - u_old).flat
return u,numpy.sqrt(numpy.dot(v,v))
if MPI.rank==0:
print("num_points: %d"%num_points)
print("dx: %f"%dx)
print("row_per_procss: %d"%rows_per_process)
m=numpy.zeros((num_points,num_points),dtype=float)
pi_c=numpy.pi
x=r_[0.0:pi_c:num_points*j]
m[0,:]=numpy.sin(x)
m[num_points-1,:]=numpy.sin(x)
l=[ m[i*rows_per_process:(i+1)*rows_per_process,:] for i in range(size)]
sendbuf=l
my_grid=MPI.COMM_WORLD.Scatter(sendbuf,root)
while num_iter < max_iter and total_err > 10e-6:
if rank==0:
MPI.COMM_WORLD.Send(my_grid[-1,:],1)
if rank > 0 and rank< size-1:
row_above=MPI.COMM_WORLD.Recv(rank-1)
MPI.COMM_WORLD.Send(my_grid[-1,:],rank+1)
if rank==size-1:
row_above=MPI.COMM_WORLD.Recv(MPI.rank-1)
MPI.COMM_WORLD.Send(my_grid[0,:],rank-1)
if rank > 0 and rank< size-1:
row_below=MPI.COMM_WORLD.Recv(MPI.rank+1)
MPI.COMM_WORLD.Send(my_grid[0,:],MPI.rank-1)
if rank==0:
row_below=MPI.COMM_WORLD.Recv(1)
if rank >0 and rank < size-1:
row_below.shape=(1,num_points)
row_above.shape=(1,num_points)
u,err =numpyTimeStep(r_[row_above,my_grid,row_below],dx,dx)
my_grid=u[1:-1,:]
if rank==0:
row_below.shape=(1,num_points)
u,err=numpyTimeStep(r_[my_grid,row_below],dx,dx)
my_grid=u[0:-1,:]
if rank==size-1:
row_above.shape=(1,num_points)
u,err=numpyTimeStep(r_[row_above,my_grid],dx,dx)
my_grid=u[1:,:]
if num_iter%500==0:
err_list=MPI.COMM_WORLD.Gather(err,root)
if rank==0:
total_err = 0
for a in err_list:
total_err=total_err+numpy.math.sqrt( a**2)
total_err=numpy.math.sqrt(total_err)
print("error: %f"%total_err)
num_iter=num_iter+1
recvbuf=MPI.COMM_WORLD.Gather(my_grid,root)
if rank==0:
sol=numpy.array(recvbuf)
sol.shape=(num_points,num_points)
##Write your own code to do something with the solution
print num_iter
print sol
For small grid sizes this will be slower than a straightforward serial implementation, this is because there is overhead from the communication, and for small grids the interprocess communication takes more time than just doing the iteration. However, on a 1000x1000 grid I find that using 4 processors, the parallel version takes only 6 seconds while the serial version we wrote earlier takes 20 seconds.
Excercise: Rewrite the above using f2py or weave, so that each process compiles a fortran or C timestep function and uses that, how fast can you get this?
